
前回

デル・アンバサダープログラムでお借りしている、実売50万円超のモンスターAI PC『Dell Pro 13 Premium』。第1回の外観・機構編に続き、第2回となる今回は、本作の目玉である最新プロセッサー『インテル® Core™ Ultra 7 268V(Lunar Lake)』が誇るAI処理能力の真価へと迫ります。
世間では『AI PC』という言葉が飛び交っていますが、『普通のPCと何が違うの?』『NPUって本当に役に立つの?』という疑問を抱いている方は少なくないはずです。
今回は、定番ツールであるOllamaやLM Studioの標準機能だけではWindows環境においてCPUが100%に張り付いてしまうという“あるあるの罠”を突破し、Intel公式のOpenVINO環境を構築して「NPU vs CPU」の同一筐体ベンチマークを敢行しました。リソース稼働率からファンの騒音値(dB)まで、数値化した結果をお届けします。
目次
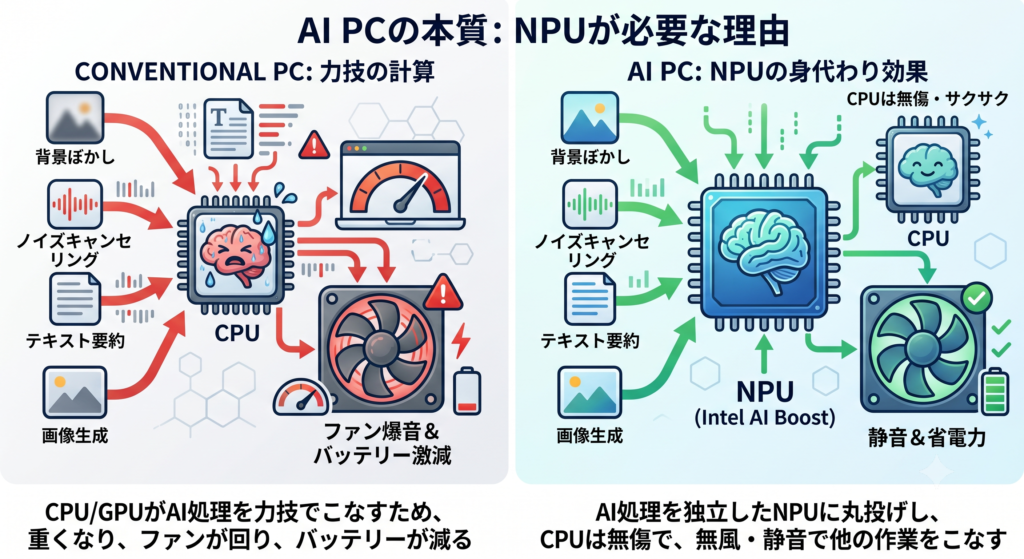
そもそも『AI PC』とは?なぜNPUが必要なのか
検証結果を見る前に、まずは『AI PC』の本質について整理しておきましょう。
従来のPCでローカルLLM(大規模言語モデル)などのAI処理を行う場合、すべての計算をメイン頭脳である『CPU』やグラフィックを司る『GPU』が力技でこなしていました。そのため、AIを動かしている間はPC全体が重くなり、ファンが爆音で回り、バッテリーが激減するという課題がありました。
これに対し、本機に搭載されているCore Ultra シリーズ2には、AI処理を専門に扱う独立した超省電力の第3の頭脳『NPU(Intel AI Boost)』が備わっています。 AI処理をこのNPUに丸投げすることで、『AIを高速駆動させながら、CPUは無傷のまま、無風・静音で他の作業を快適にこなす』ことが可能になります。これこそがAI PCの本当の価値なのです。
検証環境と使用したAIモデル
公平なテストを行うため、今回は以下の同一環境下で、計算を実行するチップ(DEVICE)だけを『NPU』と『CPU』に切り替えて測定を行いました。
- PCスペック: Dell Pro 13 Premium(Core Ultra 7 268V / 32GB LPDDR5x)
- 使用モデル:
OpenVINO/qwen2.5-7b-instruct-int4-ov(NPU向けにINT4量子化されたIntel公式モデル) - 使用ライブラリ: Intel公式
openvino-genai - 検証プロンプト: 『AIの未来について、200文字程度で簡潔に説明してください。』
NPUを確実に叩き起こすセットアップ手順
本家Ollama等の自動認識に頼るとWindowsのプロセス競合などでCPUモードにフォールバックしやすいため、今回は確実にNPUへ処理をオフロードできるIntel公式のPythonライブラリを使用しました。
ステップ1:必要なライブラリのインストール
PowerShellを開き、Intel公式のOpenVINO(GenAI)ライブラリと Hugging Face からのダウンロード用ツールを導入します。
Bash
pip install openvino-genai huggingface_hub(※Windows環境でDLLエラーが出る場合は、マイクロソフト公式の「Visual C++ 再頒布可能パッケージ」を導入してPCを再起動してください)
ステップ2:NPU最適化モデルのダウンロード
安全な作業用フォルダ(llm_testなど)に移動し、NPU専用モデルをローカルに落とします。
Python
python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='OpenVINO/qwen2.5-7b-instruct-int4-ov', local_dir='./qwen-npu')"ステップ3:測定用Pythonスクリプト(benchmark.py)の作成
初回ロード時の翻訳処理(コンパイル)をファイルに保存して、2回目以降の起動を爆速にする『モデルキャッシュ』機能を有効化したスクリプトを走らせます。
import openvino_genai as ov_genai
import time
# ==========================================================
# 項目設定:測定したいデバイスを有効にしてください
# ==========================================================
#DEVICE = "NPU"
DEVICE = "CPU"
# ==========================================================
print(f"--- Loading model onto {DEVICE} ---")
start_load = time.time()
# 💡 2回目以降のロードを爆速にするための正しい設定(キャッシュの有効化)
config = {
"CACHE_DIR": "./ov_cache"
}
# モデルの読み込み(設定を追加)
pipe = ov_genai.LLMPipeline("./qwen-npu", DEVICE, config)
end_load = time.time()
print(f"Load Time (モデル読み込み時間): {end_load - start_load:.2f} seconds\n")
# テスト用のプロンプト
prompt = "AIの未来について、200文字程度で簡潔に説明してください。"
print(f"Prompt: {prompt}\n")
print("--- Generating Response (回答生成中...) ---")
start_gen = time.time()
# 推論を実行
result = pipe.generate(prompt, max_new_tokens=250)
end_gen = time.time()
print("\n" + "="*40)
print(result)
print("="*40)
total_gen_time = end_gen - start_gen
print(f"\nGeneration Time (回答にかかった時間): {total_gen_time:.2f} seconds")【検証結果】NPU vs CPU 比較データ
複数回測定を行ったデータの平均値、およびタスクマネージャーから取得したリソース推移と騒音計アプリでの測定結果(タッチパッド手前30cmに固定して測定)をまとめました。

① 速度・ロード時間の比較
| 評価項目 | NPU (Intel AI Boost) | CPU単体駆動 | 性能差・考察 |
| モデル読み込み(初回) | 149.09 秒 | 5.73 秒 | CPUはコンパイル不要なため爆速 |
| モデル読み込み(キャッシュ有効) | 4.20 〜 4.38 秒 | 1.90 秒 | キャッシュ機能によりNPUも4秒台と実用レベル! |
| 回答生成時間(思考・出力) | 11.70 〜 12.26 秒 | 14.92 〜 15.74 秒 | NPUの方が約 22% 高速に回答を出力 🚀 |
② タスクマネージャーの負荷と騒音の連動
AIがテキストを生成している最中の、各チップの稼働率とファン騒音の推移です。ここに決定的な差が生まれました。
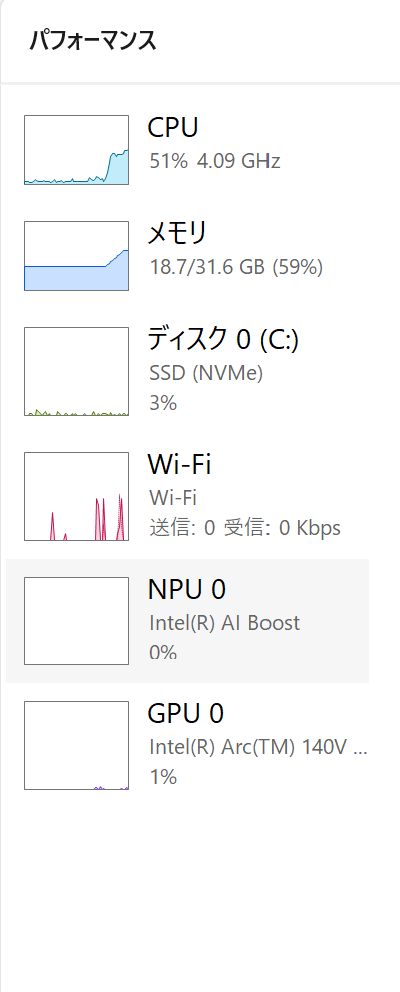
CPU稼働時
CPU使用率が 4% → 51% へ急上昇。メインの計算資源の半分がAIに占有されます。それに伴い、静かだった部屋(通常時36dB)にファンが勢いよく回り出し、はっきりと音が認識できる 42dB まで騒音値がアップしました。
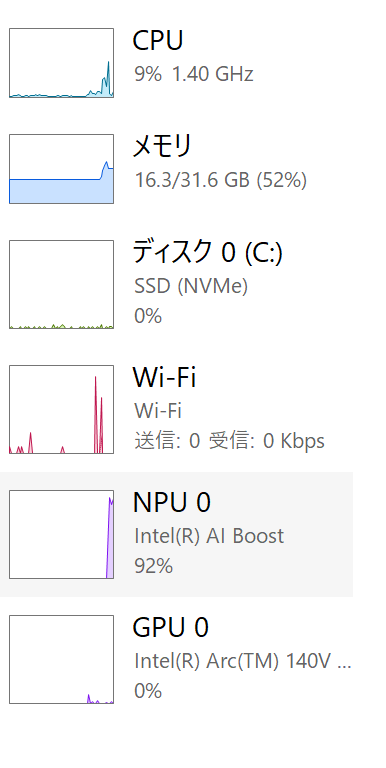
NPU稼働時
CPU使用率は 4% → 9% とわずか5%の増加に留まり、ほぼアイドル状態の軽さを維持。代わりにNPU(Intel AI Boost)が 0% → 92% でフル駆動します。これだけフル稼働しているにもかかわらず、ファンの音は集中を妨げないささやき声レベルの 39dB に抑制されました。
考察:数値から見えた『NPUの本当の価値』
初回ロード149秒の正体と『キャッシュ』の重要性
初めてNPUモードで動かした際、ロードに2分半(149秒)もかかり絶望しかけました。しかしこれは汎用計算機であるCPUと違い、特定の行列計算に特化したNPUへモデルの数式を最適化(コンパイル)するための、OpenVINO推論エンジンの正常な仕様です。
2回目以降は、コンパイル結果を保存する『モデルキャッシュ』のおかげで4秒台まで短縮されるため、実用上のストレスは全くありません。
『CPU稼働率9%』がもたらす極上の作業環境(QOW向上)
CPU駆動時の51%という負荷は、PCが常に重いタスクをバックグラウンドで処理している状態です。この状態でメインのコーディング作業、コンパイル、あるいはブラウザで大量のタブを開くと、確実にシステムの挙動がカクつきます。
しかしNPU駆動なら、裏でAIにドキュメント作成や仕様書の要約をガシガシ実行させていても、CPUはわずか9%しか使っていません。『AIをバックグラウンドで走らせながら、自分は表で何事もないかのように100%のパフォーマンスで作業を続けられる』、これこそが開発ワークフローやドキュメント自動化を支える次世代PCの姿です。
3dBの差が意味する『音エネルギー半分』の静音性
音の単位であるデシベル(dB)は対数で計算されるため、『3dBの差』は音のエネルギー(空気の振動)において約2倍の差に相当します。
第1回レビューでご紹介した『1.5°のヒンジ傾斜』によって確保された裏面の吸排気スペースが、NPUの優れた電力効率と合わさることで完璧な熱マネジメントを実現しています。42dB(CPU駆動)は静かなオフィスでもファンが回ったことがはっきり自覚できるレベルですが、39dB(NPU駆動)は深夜のリビングやカフェで使っても周囲の邪魔に全くなりません。
まとめ:ローカルAI時代のインフラとして
今回の検証を通して、Dell Pro 13 Premiumが誇る最新のAI PCとしてのポテンシャルが見えてきました。
- 速度: CPUより 約22%高速(15.3秒 → 11.9秒)
- 効率: CPUの負荷を 約10分の1に削減(47%増 → 5%増)
- 静音: ファンの音のエネルギーを 半分に抑制(42dB → 39dB)
ただAIが動くだけでなく、PC本来の軽快さを1ミリも損なわずにAIの恩恵を共存させられる。50万円を超えるプレミアムな価格の裏には、こうした『限界まで高められた仕事の質(QOW)』を支える確かなハードウェアとアーキテクチャの進化がありました。
ローカル環境で安全かつ快適にAIを相棒にしたいビジネスパーソンにとって、この静かでパワフルな挙動は間違いなく強力な武器になります。
次回は、この快適な環境をフルに活かし、『カフェや出張先など、屋外での極限の生産性ワークスタイル』において、本機がどれほどのQOL・QOWをもたらすのかを実戦レビューしていきます。お楽しみに!
